Python 抓取PTE羊驼APP
批量抓取羊驼App里的不同学习模块的资料,并保存至本地。
这样可以有助于自己将资料整理成适合自己学习方法。
羊驼PTE只有APP端,不同于萤火虫PTE的web的端口。
因此第一步是需要分析羊驼APP,捕获它所request的HTTPS请求,并分析出对应的API接口。
一般APP的数据接口格式是json格式。
在第一步中需要用到Fiddler 请求分析软件,在本机通过模拟器方式运行羊驼PTE。
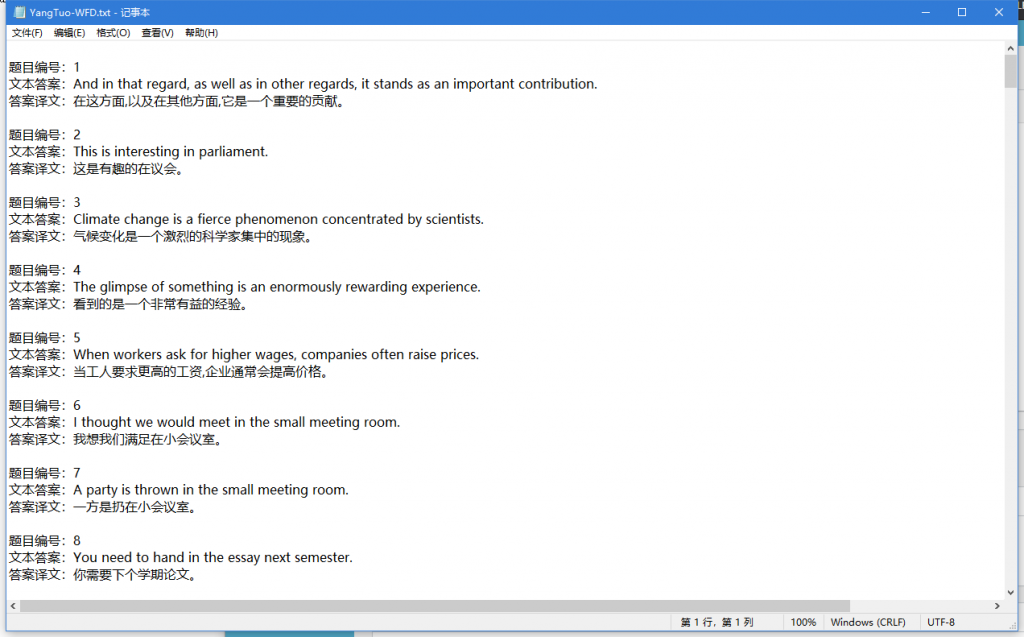
本次展示抓取听力模块中WFD的资料,如下图。
在Fiddler中可分析得出点击WFD的Item时会发送一条request对应题目的去服务器请求对应的详细内容。
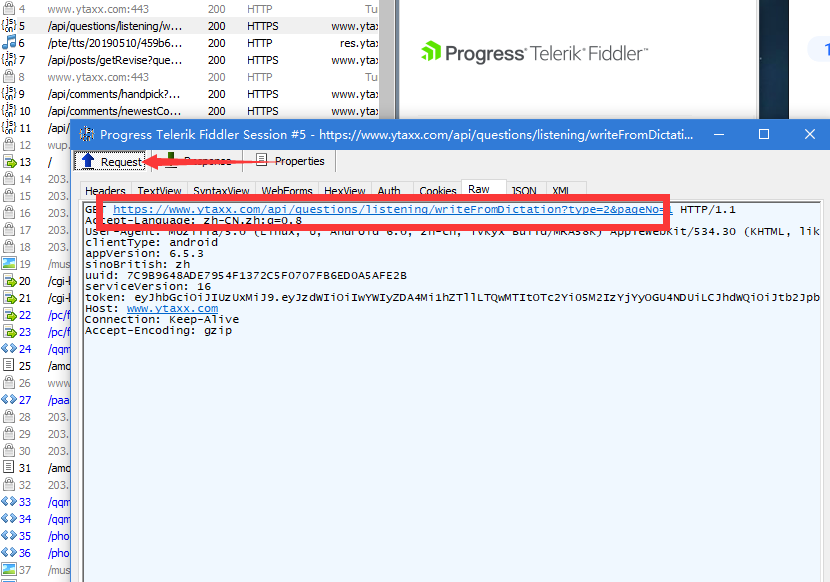
再通过查看response可以发现json中出现所请求的数据报文,该报文即为所需抓取的详细数据。
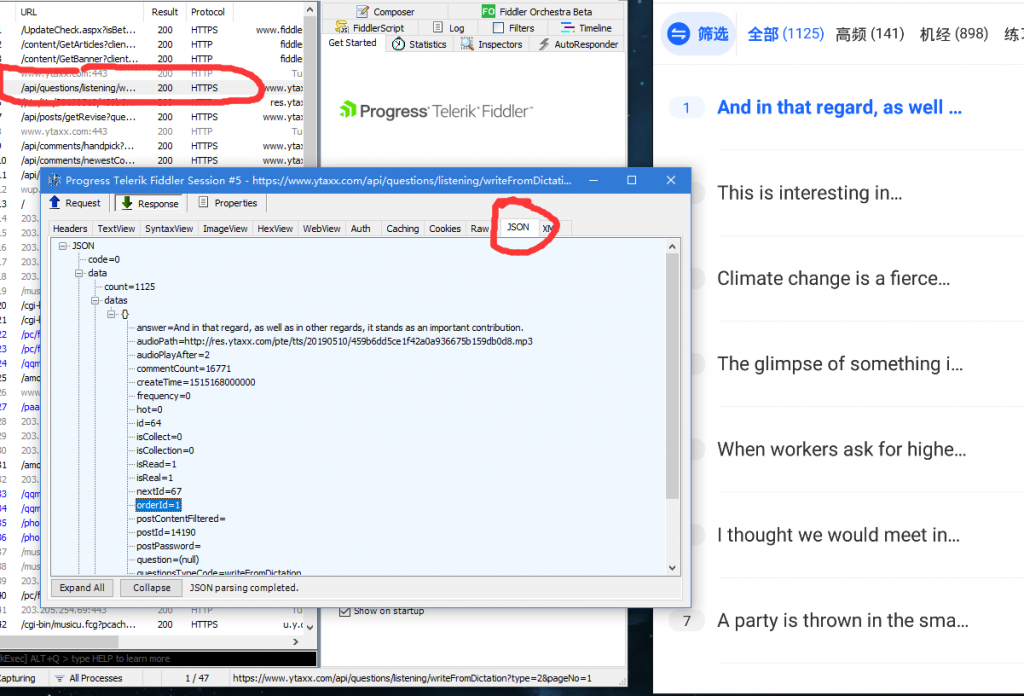
至此,可以得出WFD列表中每个Item的数据API为:https://www.ytaxx.com/api/questions/listening/writeFromDictation?type=2&pageNo=1
其中PageNO为题目ID,ID区间为1-1125。
第二步,编写一个Python的下载工具,即可批量下载。
API中的数据为json格式,如下图

对于此json转化为数组并提取为对应的字符串即可
题目ID :[‘data’][‘datas’][0][‘orderId’]
题目答案:[‘data’][‘datas’][0][‘answer’]
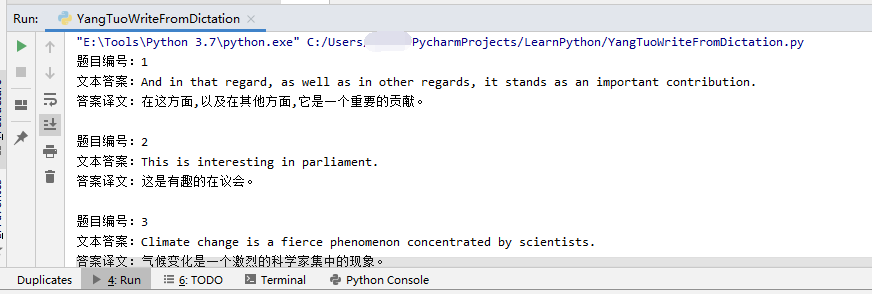
仅供展示,抓取的数据直接存入TXT文档了。
需要方便查看的也可以在python利用Excel模块直接生成Excel。